基于知识库系统的智能搜索引擎研究
 2010-01-25 21:59
2010-01-25 21:59
邱均平,余以胜
(武汉大学中国科学评价研究中心,湖北武汉430072)
摘要:本文分析了传统搜索引擎的弊端,探讨了利用知识库系统设计智能搜索引擎的方法,介绍了一个知识库系统(CYC系统)的应用实例。
关键词:搜索引擎;智能搜索;知识库系统
中图分类号:G250.73 文献标识码:A 文章编号:1007-7634(2006)03-0413-04
1 引言
随着全球网络化、信息化的发展,网络上的信息越来越多,现在Internet上有上亿的网页,内容十分丰富,形式也是多样,而且处于时时变化之中。Internet在自身发展的同时也促进了搜索引擎技术的不断发展,各类搜索引擎在Internet中大显身。但是,目前的搜索引擎存在着不少局限性,最突出的表现为返回的查询结果太多,用户难以快速找到所需的信息,如果缺乏有效的信息检索手段,最终必将影响网络的应用。国外的第一代搜索引擎如雅虎、AltaVista等已取得了巨大成功,一些新的搜索引擎如Askjeevs、Google、Gurunet、Great2searches等也进入了实用阶段,它们的特征是使用了一系列新技术,特别是自然语言处理技术来使搜索更加智能,信息查找更加容易,给用户的信息服务更加综合。
2 传统搜索引擎
搜索引擎由信息抽取系统和用户界面组成。传统搜索引擎一般有两种信息检索方式:一种是目录式搜索引擎,这种方式采用目录树分类方式,用户登录的网站属于至少其中某一个类别。由于使用了人(专家)的智力来对网站进行归纳和分类,所以搜索的信息比较准确,导航质量比较高,但是它除了成本较高之外,对网站的描述也十分简略,不能深入网站的内部细节,因此用户查询不到网站内部的重要信息,容易造成信息丢失,而且由于人工编辑能力有限,往往导致网站信息陈旧,数据库更新不及时等问题。二是使用全文检索技术,全文检索技术处理的对象是文本,它能够对大量文档(这里是大量网页数据)建立由字(词)到文档的倒排索引,在此基础上,用户使用关键词来对文档(网页)进行查询时,系统将给用户返回包含该关键词的网页。全文检索是一个很成熟的技术,它能够解决对网页细节的检索问题,但这又易导致返回的信息太多,同时基于关键字匹配的搜索技术有较大的局限性,它不能区分同行异义,其次不能联想到关键字的同义词。另外,还有一种常用的搜索引擎是元搜索引擎(MetaSearchEngine)。元搜索引擎其自身没有网页搜寻机制,也没有自己独立的索引数据库,但元搜索引擎可以将多个独立搜索引擎集成在一起,并对各个独立搜索引擎返回的检索结果进行整理、去重,然后反馈给用户,所以元搜索引擎可以大大提高检索效率,但元搜索引擎从本质上并不能克服上面两种搜索引擎所固有的弊端。
3 基于知识库系统的智能搜索引擎特征
通过上面的分析我们可以看出:当前搜索引擎所使用的技术都难以解决“找信息难”的问题,造成这种困难的关键在于搜索引擎缺乏知识处理和理解能力,把信息检索从目前基于关键词层面提高到基于知识(或概念)层面,是解决问题的关键。
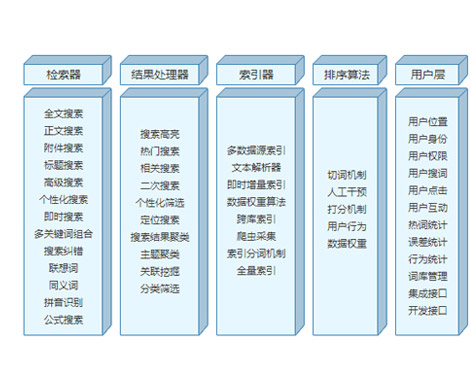
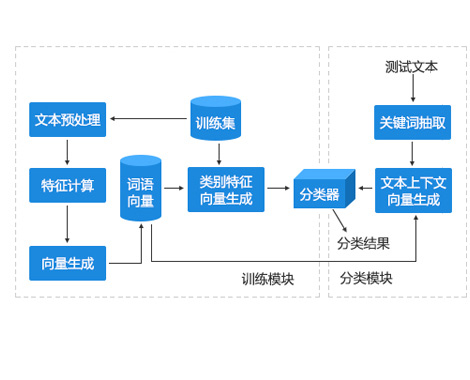
新一代基于知识库系统的智能搜索引擎作为一种高效搜索引擎技术,在当今网络信息时代日益引起人们的关注。我们提出基于知识或概念层面来提高搜索引擎智能水平的方法,建立一种基于内容的搜索引擎,通过搜索引擎技术与语言学的结合,开发检索专用字典或是通过全文扫描和词间关系的分析,实现搜索引擎对搜索词在语义层次上的理解。这里的知识或概念分为两个层面,第一个层面的知识实质上是人的认知知识,它实际上就是一个巨大的知识库或概念图,存放的是人的知识,包括各种知识、概念以及知识、概念之间的种种关系。在计算机上实现时,这个知识表示为一种语义知识。第二个层面的知识是Internet上的所有信息,它的信息是搜索引擎要检索和查询的对象。基于语义知识的Internet信息检索,能够使搜索引擎从基于关键词的搜索提高到基于知识的检索。与传统基于关键词的检索手段相比,它有着显著的优势:基于关键词的传统信息检索以词串匹配的方式来检索互联网信息,如图1所示。必然导致信息检索困难;基于语义知识的信息检索,先把用户的检索映射到语义知识中,从语义知识获取相关知识和联想后,再到互联网进行信息检索。基于知识内容的搜索不是根据字型,而是试图理解用户的请求,同时根据文档的内容选出符合用户要求的文档,这是一个基于知识的信息检索过程,如图2所示。它能够使用户对要检索的东西定位得更快、了解得更深入。所谓的理解包括:用户查询的理解和文档内容的理解,它允许用户用非常自然的形式提出查询请求,引擎采用语义知识、汉语分词技术等分析用户的请求,了解用户真正的需求。实际上,这种检索的实质就是以有序的知识库(人的知识)对无序的知识库(Internet)。一般而言,智能搜索引擎有如下几个主要特征。
(1)智能网络蜘蛛在线搜索能力。网络蜘蛛(netspider)通过启发式学习采取最有效的搜索策略,选择最佳时机获取从Internet上自动收集、整理的信息。网络信息时刻在动态更替,即使在搜索过程中,文档也会被添加、删除、改变。因此,智能引擎有一个设计网络蜘蛛,自动完成在线信息的索引。搜索引擎能在Internet或Intranet的任何地方、任何时候,尽可能地挖掘和获得信息,网络蜘蛛既可收集特定站点的信息,又能遍历整个Inter2net,对整个Internet进行索引。为提高搜索速度,类似于元搜索引擎技术,智能搜索引擎可以同时启动多个引擎并行工作,将各个引擎的搜索结果进行整合,作为一个整体存放到索引数据库中。
(2)搜索引擎人机接口的智能化。智能搜索引擎可以通过自然语言和用户交互,它采取诸如语义知识、知识库系统等智能技术,通过汉语分词、句法分析以及统计理论有效地理解用户的请求,并对搜索结果进行合理的解释,甚至能体会出用户的弦外之音,最大程度地了解用户的需求。
(3)利用push技术为用户提供个性化服务。利用搜索引擎的push技术,为特定的用户提供定题服务,可以充分发挥智能搜索引擎的主动性。智能搜索引擎能够观察用户的行为,了解用户的兴趣爱好,并通过不断的训练、学习增长智能,每次用户对搜索引擎返回的信息有一定的评价,智能引擎可以根据用户评价的反馈信息,不断调整自己的行为,为用户提供更为满意的信息服务。智能搜索引擎还可以在任何特定的时候(如用户最关心的信息发生了某种变化的时候)用各种方法与用户取得联系,并选择恰当的方法跟用户通信。
(4)具有支持Agent的能力。由于Web服务器端有综合性知识库,为智能Agent的活动提供了基础。例如,活动在客户端的Agent可对用户正在浏览的网页进行主动观察、分析内容,根据服务器端的知识库来推荐内容相近的其他网页供用户参考。
(5)跨平台,多文档处理能力。智能搜索引擎具有跨平台和多混合文档的处理能力。不仅能够处理结果化文档,还能够处理Internet上的非结构化文档(图象,声频和视频)。既能处理HTML(Hy2perTextMarkupLanguage,超文本标志语言)、XML(eXtendedMarkedLanguage,扩展标志语言)和SGML(StandardForGeneralMarkupLanguage)文档,还能处理其它类型的文档,譬如Word、WPS等。一些搜索引擎可以提供多媒体的搜索,但目前还是依赖与超文本文件中的标记和文本信息进行处理,对于视频文件的基于内容的搜索技术已经有了一些积累,但距离在互联网上的实用还有一定的差距。另外智能搜索引擎应该支持多语言搜索,允许用户使用中文,英文或其他语言进行输入和查询。譬如Google搜索引擎既支持中文,也支持英文和其他多种语言,同时也支持中文简体和繁体,同时可以支持中英文混合搜索,给用户的查询带来极大的方便。
4 新一代智能搜索引擎实现技术
目前实现真正意义上的智能搜索引擎在技术上还有一定的困难,因为语义知识库的建立涉及到人工智能(ArtificialIntelligence)、本体论(Ontology)、知识库系统和知识工程(KnowledgeEngineering)等多方面的技术。知识工程发展于工程领域,其不仅可以解决单个领域的知识,而且主要面向于解决多领域的知识过程和建立知识模型,比如:特征模型、数字模型、影像模型和人工神经网络。知识工程不仅可以获取和表述知识,更为主要的是强调知识的整体性。自从Internet出现后,尤其是WWW的迅猛发展,知识工程所研究的内容、对象和方法发生了很大的变化。当前的知识库系统,是建立在以网络计算环境下的知识表示、组织、管理和利用,不仅包括常识性知识,还应当包括专业性知识,下面就是当前智能搜索引擎在知识库系统中所采用的一些技术。
(1)短语识别技术。用短语描述查询请求的情况很常见,但因为汉语词组的复杂性,所以在中文搜索引擎中,我们不能象英文词组一样简单的将中文短语分离成词组。譬如查询条件“武汉的大学”,“武汉”和“大学”存在一定的关系,但如果不将“武汉”和“大学”联合起来作为一个短语查询,那么除了选出关于“武汉的大学”的文档之外,还将查出有关“武汉”和“大学”的冗余文档。因此,短语识别是智能化引擎应当解决的一个重要问题。
(2)汉语分词技术。关键词查询的前提是将查询条件分解成若干关键词。对英文而言,一个单词就是一个词,但中文词之间的关系却复杂得多,主要问题是中文词与词之间没有界定符,需要人为切分,但人为的切分有很大的灵活和操作性,往往容易产生词义失真。此外汉语中存在大量的歧义现象,对几个字分词可能有好多种不同的结果,而且简单的分词往往会完全曲解甚至误解用户查询的真正意图,造成误检和漏检。因此,可以利用语义知识库进行总结,获得每个词出现的概率以及词与词之间的关联信息,就可能有效地排除各种歧义,大幅度提高分词的准确性,从而准确地表述查询请求和文档信息。
(3)同义词处理。汉语词语之间复杂性的另一个方面是同义词的问题,同一个词组往往有许多不同的意思,处理同义词的一种方法是在语义知识库中人工构造同义词表,对专用领域的搜索引擎,这种方法是非常有效的。另外一种方法是从语义知识库中自动取得同义词关系,给出一个查询的关键词,搜索引擎能主动“联想”到与其同义或意思相近的词。此外,还有一些其他的人工智能方法,譬如可以将知识库和推理机应用到搜索引擎中,所有这些都是实现信息时代对搜索引擎智能化挑战的有效手段。
5 应用实例
知识工程(KE,KnowledgeEngineering)是人工智能专家费根鲍20世纪70年代后期提出的。作为人工智能学科的一个分支,它主要研究知识的表示、获取、组织、管理和利用等,提供大量的用户和专业领域应用的背景知识。经过10多年的发展变化,其基本理论与技术都已逐渐趋向成熟,CYC系统就是一个例子。
CYC系统是由美国CYCorp公司开发的一套最新的知识库系统。CYC系统研究的目标是通过知识工程的手段,让计算机建立起和人一样的常识系统,如知道树是长在房子外面的,并且把这样的系统用于实际应用中,如搜索引擎的智能化,可以说CYC是一个人类常识的知识库。CYC知识库将大量人类知识(比如事实、推理等)规范化表示,其中的断言(包括简单的断言和规则)将术语结合起来进行推理。CYC知识库系统对自然语言处理有很大的帮助,因为对于含有模糊或复杂语法的句子,CYC可以利用自己对常识的理解进行正确的语法分析,CYC的自然语言处理器包括三部分:词典、句法分析器以及语义解释器。有了自然语言处理器,我们就可以用自然语言进行数据库的查询,更方便地进行搜索,并提供友好的搜索引擎人机界面。另外由于计算机中数据存储有多种形式(结构化、半结构化以及非结构化),CYC可以将其中的一部分转化为可用的知识,这些知识通过语义综合总线联入CYC系统,CYC将数据库中的记录和知识库中的断言相联系,在推理的过程中,对记录进行自然语言处理,然后到知识库中为它所涉及到的断言进行定位。未来的CYC系统将是具有人类常识辩解能力的、同时又专注于不同领域、具有不同推理和事务解决能力特长的计算机专家系统,其在人工智能的许多领域,尤其是在搜索引擎的智能化开发中将会有更广阔的应用前景。
6 结语
智能搜索引擎技术在未来的发展中,将不断完善当前搜索引擎的功能和特性,同时将结合人工智能、知识工程和网络分布计算等领域的研究成果,提出一些新的研究方向,如可视化智能搜索引擎等。同时,随着Internet上信息量的不断增大和计算机运算速度的加快,智能搜索引擎技术将是信息检索的发展趋势。